
PC-GNN
论文地址:Pick and Choose: A GNN-based Imbalanced Learning Approach for Fraud Detection (acm.org)
代码仓库:PonderLY/PC-GNN: (WWW 2021) Source code of PC-GNN (github.com)
1.背景
图结构中的欺诈节点数量通常远少于正常节点,导致传统的图神经网络在处理这种不平衡数据时表现不佳,特别是难以识别重要的少数类。
2.贡献
- 提出了基于GNN的解决类别不平衡问题的新方法,适用于图结构的欺诈检测。
- 设计了标签平衡采样器和邻居选择采样器,能够更有效地捕捉少数类(欺诈类)的重要特征。
- 在多种数据集上进行了大量实验,证明了该方法的有效性。
3.方法
文章提出了一种名为Pick and Choose Graph Neural Network(PC-GNN)的方法,专门针对图数据的不平衡分类任务。该方法通过以下步骤来提高欺诈检测的准确性:
Pick(挑选):使用一个标签平衡的采样器,从图中挑选节点和边,构建一个小的子图用于训练。这种采样方式使得子图中的类别分布更加均衡,特别是提高了少数类节点被选中的概率。
Choose(选择):为每个节点选择合适的邻居节点,通过一个可学习的距离函数来挑选邻居,过滤掉不相关或误导性的链接(如正常用户伪装成欺诈者的情况),并增加与目标节点相似的欺诈邻居。
Aggregate(聚合):将挑选出来的邻居信息进行聚合,并在不同关系下融合这些信息,得到目标节点的最终表示。


3.1 标签平衡采样器(Pick: Label-balanced Sampler)
在Pick步骤中,作者提出了一个标签平衡采样器(Label-balanced Sampler),用于从原始图中选择节点和边,以构建用于子图训练的子图。该方法的主要目的是在样本标签严重不平衡的情况下,增加少数类节点被采样的概率,从而改善训练过程中由于类别不平衡引起的问题。
公式
给定一个包含多种关系的图 $G = (V, E, A, X, C)$,其中:
- $V$ 表示节点的集合,
- $E$ 表示边的集合,
- $A = \sum_{r=1}^{R} A_r$ 是 $R$ 种关系的邻接矩阵之和,
- $X$ 是节点特征矩阵,
- $C$ 是节点的标签集合。
首先计算图的归一化邻接矩阵 $\hat{A}$,其定义为:
其中 $D$ 是一个对角矩阵,其对角元素为每个节点的度。该归一化过程有助于平衡不同节点之间的连接强度,从而避免度大的节点在信息传递过程中占据主导地位。
对于图中的每个节点 $v \in V$,我们根据以下公式定义其被采样的概率 $P(v)$:
公式中的各项含义如下:
- $\hat{A}(:, v)$ 是归一化邻接矩阵中第 $v$ 列的向量,它反映了节点 $v$ 在图中的连接模式和重要性。我们计算 $|\hat{A}(:, v)|_2$ 的 $L_2$ 范数,以衡量节点 $v$ 在图结构中的显著性。
- $LF(C(v))$ 表示节点 $v$ 所属类别 $C(v)$ 的标签频率,即该类别在整个图中的出现频率。通过使用标签频率的倒数,少数类的节点会有更高的采样概率,从而在子图中使得少数类和多数类的节点数目更为平衡。
通过上述公式,节点的采样概率不仅考虑了其在图结构中的位置(通过 $|\hat{A}(:, v)|_2$),还结合了标签的不平衡性(通过 $LF(C(v))$),确保少数类的节点有更高的概率被选中。
子图构建
根据采样概率 $P(v)$,我们从原始图 $G$ 中采样节点,得到节点集合 $V_p$,进而构建子图 $G_p$,其形式为:
其中,$V_p$ 是采样到的节点集合,$E_p$ 是 $V_p$ 中节点之间的边集合,$A_p$ 是相应的邻接矩阵,$X_p$ 是采样节点的特征矩阵,$C_p$ 是采样节点的标签集合。
构建子图的一个关键点在于,子图中节点的标签分布更趋向于平衡(即少数类节点的数量增加),这使得在训练过程中,模型能够更好地学习到少数类的特征,避免少数类的特征在多数类的噪声中被淹没。
效果
通过这种基于标签平衡的采样方法,生成的子图中的节点标签分布会更加均衡。这对于训练深度学习模型尤其是图神经网络(GNN)非常重要,因为在图中的信息传递和特征聚合过程中,少数类节点的特征往往会被多数类的特征所掩盖,而该方法能够有效缓解这种问题。
3.2 邻居选择采样器(Choose: Neighborhood Sampler)
在Choose步骤中,作者提出了一种邻居选择采样器(Neighborhood Sampler),用于在采样的子图中选择合适的邻居节点。这一步的核心是通过对多数类邻居进行下采样,对少数类邻居进行过采样,以提升图神经网络在不平衡数据上的表现,尤其是少数类节点的表示能力。
公式
在 Pick 步骤采样得到子图 $G_p = (V_p, E_p, A_p, X_p, C_p)$ 后,下一步需要选择适当的邻居节点进行聚合。对于每个节点 $v \in V_p$,我们从其邻居中选择合适的节点进行信息传递和特征聚合。具体定义如下:
给定节点 $v$ 在关系 $E_r$ 下的邻居集合 $N_r(v)$,其定义为:
即在关系 $r$ 下,所有与节点 $v$ 通过边 $A_r(v, u)$ 连接的节点 $u$ 构成了 $v$ 的邻居集合。
为了应对类不平衡问题,原始的邻居定义 $N_r(v)$ 可能包含大量的多数类邻居或缺少对少数类邻居的识别。因此,我们在选择邻居时进行以下两步操作:
多数类的下采样:对于属于多数类的节点 $v$,我们通过距离函数过滤掉与其距离较远的邻居,定义为:
其中,$D(v, u)$ 表示节点 $v$ 与 $u$ 之间的距离,$\rho^-$ 是一个距离阈值,用于过滤掉与目标节点距离较远的邻居,从而减少多数类节点的噪声影响。
少数类的过采样:对于属于少数类的节点 $v$,我们不仅从 $N_r(v)$ 中选择原始邻居,还可以添加一些与 $v$ 不直接相连但具有相似特征的少数类节点,定义为:
其中,$\rho^+$ 是用于确定少数类节点的距离阈值,$C(u)$ 和 $C(v)$ 表示节点 $u$ 和 $v$ 的类别。这样可以增加少数类节点的数量,使其在特征聚合时能够获得更多有用的上下文信息。
距离函数
在多数类的下采样和少数类的过采样过程中,我们使用了距离函数 $D(v, u)$ 来判断邻居节点与目标节点之间的相似性。为了在隐藏空间中度量节点的距离,作者采用了参数化的距离函数,定义如下:
其中:
- $h_v^{(\ell),r}$ 和 $h_u^{(\ell),r}$ 是节点 $v$ 和 $u$ 在第 $\ell$ 层的嵌入表示(在关系 $r$ 下),
- $U_r^{(\ell)}$ 是参数矩阵,用于学习节点嵌入的转换,
- $\sigma$ 是一个激活函数,用于预测节点为欺诈的概率。
该距离函数通过计算目标节点 $v$ 和邻居节点 $u$ 在潜在嵌入空间中的差异来衡量它们的距离。如果节点的标签相同且距离较小,它们更可能被选为邻居。
邻居采样
根据距离函数的定义,多数类和少数类的邻居采样规则分别如下:
多数类的下采样邻居集合:
少数类的过采样邻居集合:
最终,少数类的目标节点 $v$ 的邻居集合为原始邻居和过采样邻居的并集:
学习
距离函数是可学习的,其中的参数 $U_r^{(\ell)}$ 会随着训练过程进行优化。我们使用交叉熵损失函数来优化距离函数的参数,定义为:
其中,$p_v^{(\ell),r}$ 是节点 $v$ 在第 $\ell$ 层、关系 $r$ 下被预测为欺诈的概率,$y_v$ 是实际的标签。
解释
多数类下采样:通过对多数类节点的邻居集合进行下采样,避免了多数类的噪声干扰,减少了它们对少数类节点表示学习的负面影响。
少数类过采样:通过对少数类节点的邻居集合进行过采样,可以增强少数类节点的特征学习,使其在信息传递和聚合过程中获得更多的有效信息。
距离函数的作用:距离函数不仅考虑节点的嵌入表示,还结合了节点的标签信息,确保相似的少数类节点能够相互影响,而相异的多数类节点则被过滤掉。
效果
通过这种邻居采样策略,少数类节点的特征不会在多数类节点的噪声中被淹没。同时,通过对多数类节点的下采样,减少了多数类邻居对少数类节点特征的稀释效应。结合距离函数的参数化设计,使得采样过程具备自适应性,能够动态调整邻居选择,从而提高模型在不平衡图数据上的表现。
3.3 算法结构

输入:
- $G = (V, E, A, X, C)$:一个多关系的不平衡图,其中 $V$ 是节点集,$E$ 是边集,$A$ 是邻接矩阵,$X$ 是节点特征,$C$ 是节点的标签集。
- $V_{\text{train}}$:训练集节点。
- $N_p$:每个 epoch 中采样的节点数量。
- $N_{\text{epoch}}$:总的训练 epoch 数量。
- $N_{\text{batch}}$:每个批次的训练节点数量。
- $L$:神经网络层数。
- $d_\ell$:第 $\ell$ 层的维度。
输出:
- 每个节点的最终表示 $h_v^{(L)}$,其中 $v \in V$。
算法流程:
初始化:
- 初始化每个节点的初始特征为 $h_v^{(0)} \leftarrow x_v$。
- 根据节点的标签频率 $LF(C(v))$ 和归一化邻接矩阵 $\hat{A}$ 来计算每个节点 $v$ 的采样概率:
训练循环(重复 $N_{\text{epoch}}$ 次):
- 采样节点:根据采样概率 $P(v)$ 从训练集 $V_{\text{train}}$ 中采样 $N_p$ 个节点,得到采样节点集 $V_p$。
计算批次数量:根据采样节点的数量 $|Vp|$ 和每批次节点数 $N{\text{batch}}$,计算批次数量 $B$:
批次训练:对于每个批次 $b = 1, 2, \dots, B$:
- 构建子图:从采样的节点 $V_b$ 及其之间的边 $E_b$ 构建子图 $G_b = (V_b, E_b)$。
- 逐层计算:对于每一层 $\ell = 1, 2, \dots, L$:
- 对于每个关系 $r = 1, 2, \dots, R$:
- 邻居采样:
- 如果节点 $v$ 属于多数类,则对其邻居进行下采样:
- 如果节点 $v$ 属于少数类,则对其邻居进行过采样:
- 更新节点表示:根据 Eq. (8) 更新节点 $v$ 在关系 $r$ 下的表示 $h_v^{(\ell),r}$。
- 邻居采样:
- 更新全局节点表示:根据 Eq. (9) 聚合来自不同关系的邻居信息,更新节点 $v$ 在第 $\ell$ 层的表示 $h_v^{(\ell)}$。
- 对于每个关系 $r = 1, 2, \dots, R$:
返回结果:
- 最终,经过 $L$ 层的计算,返回每个节点 $v \in V$ 的表示 $h_v^{(L)}$。
解释:
- 采样策略:通过 Pick 阶段的标签平衡采样器,确保少数类节点在每个 epoch 中更有可能被采样,进而缓解类不平衡问题。
- 邻居选择策略:Choose 阶段中的邻居采样器通过对多数类节点的邻居进行下采样、对少数类节点的邻居进行过采样,确保少数类节点在特征聚合过程中能够获得更多有效信息。
- 逐层计算:通过逐层对不同关系下的邻居信息进行聚合,PC-GNN 能够充分利用图结构中的多关系信息,提升节点的表示学习效果。
总结:
PC-GNN 通过 “Pick” 和 “Choose” 两个步骤来解决图结构数据中的类不平衡问题。Pick 阶段通过标签平衡采样,确保少数类节点优先被选取;Choose 阶段通过灵活的邻居选择策略,提升少数类节点的特征学习效果。这一框架在不平衡数据的节点分类任务中表现出色,尤其适用于欺诈检测等任务。
3.4 Aggregate: 信息聚合架构
在进行Pick和Choose步骤之后,PC-GNN采用消息传递架构进行信息聚合。目标是通过从每一层和每种关系中聚合邻居节点的信息来更新节点的嵌入表示。
信息聚合的步骤:
信息聚合步骤分为两个部分:
在每种关系下的信息聚合:
- 对于每一层 $\ell$,在每个关系 $r$ 下,聚合节点 $v$ 从选定邻居接收到的信息,表示如下:
- $h_v^{(\ell),r}$ 表示节点 $v$ 在第 $\ell$ 层、关系 $r$ 下的表示。
- $\text{AGG}_r^{(\ell)}$ 是第 $\ell$ 层关系 $r$ 下的聚合函数(通常是平均聚合器)。
- $\oplus$ 是特征拼接操作。
- $W_r^{(\ell)}$ 是第 $\ell$ 层关系 $r$ 下的权重矩阵。
- $\text{ReLU}$ 是激活函数。
- 对于每一层 $\ell$,在每个关系 $r$ 下,聚合节点 $v$ 从选定邻居接收到的信息,表示如下:
关系间的信息聚合:
- 聚合来自不同关系的信息后,再结合前一层的表示,得到节点 $v$ 在第 $\ell$ 层的最终表示:
- $h_v^{(\ell),1}, \dots, h_v^{(\ell),R}$ 表示节点 $v$ 在不同关系下的嵌入表示。
- $W^{(\ell)}$ 是聚合不同关系后更新的权重矩阵。
- $h_v^{(\ell-1)}$ 是节点 $v$ 在上一层的嵌入表示。
- 聚合来自不同关系的信息后,再结合前一层的表示,得到节点 $v$ 在第 $\ell$ 层的最终表示:
解释:
- 关系内聚合:通过在每种关系下从邻居中获取信息,节点的表示能够更好地捕获特定关系下的局部结构信息。
- 关系间聚合:通过在每一层聚合不同关系下的表示,PC-GNN能够将多关系的信息综合起来,生成更加丰富的节点表示。
总结:
PC-GNN的消息传递架构分为两个步骤:首先在每种关系内聚合信息,然后在每一层聚合来自所有关系的信息。这种结构能够有效地捕捉图中的多关系信息,并为每个节点生成更具区分性的嵌入表示。
3.5 Training: 模型训练
在信息聚合步骤之后,PC-GNN通过一个MLP分类器进行训练,并最小化交叉熵损失来学习模型参数。
训练步骤:
交叉熵损失:
- 使用图神经网络生成的嵌入表示来进行节点分类,使用的损失函数为交叉熵损失:
- $y_v$ 是节点 $v$ 的真实标签。
- $p_v$ 是节点 $v$ 被预测为欺诈的概率。
- 使用图神经网络生成的嵌入表示来进行节点分类,使用的损失函数为交叉熵损失:
距离损失:
- 在邻居选择步骤中,使用了一个基于距离的学习模块。为了优化该模块的参数,采用了额外的距离损失函数:
- $p_v^{(\ell),r}$ 是节点 $v$ 在第 $\ell$ 层、关系 $r$ 下被预测为欺诈的概率。
- 在邻居选择步骤中,使用了一个基于距离的学习模块。为了优化该模块的参数,采用了额外的距离损失函数:
总损失函数:
- 最终的损失函数结合了GNN的分类损失和距离损失,通过一个平衡系数 $\alpha$ 进行加权:
训练流程:
- 通过上述损失函数对模型参数进行优化,使用梯度下降方法进行训练。
- 训练过程中,模型在每一层对邻居信息进行聚合,并更新节点的嵌入表示。
总结:
PC-GNN的训练过程通过最小化分类损失和距离损失来优化模型。分类损失确保模型能够正确预测节点的类别,而距离损失帮助模型优化邻居选择的参数,使得模型在处理不平衡数据时更加鲁棒。
4.实验验证
实验整体流程和效果概述
本部分实验的目的是验证所提出的PC-GNN模型在图结构的不平衡节点分类任务中的有效性,尤其是在欺诈检测等任务中的性能表现。作者设计了一系列实验来回答以下几个关键问题:
- RQ1:PC-GNN 能否优于现有的图异常检测方法?
- RQ2:PC-GNN 的关键组件对预测有何影响?
- RQ3:PC-GNN 对不同训练参数的表现如何?
- RQ4:将提出的模块应用于其他GNN模型时是否能提升性能?
整体流程:
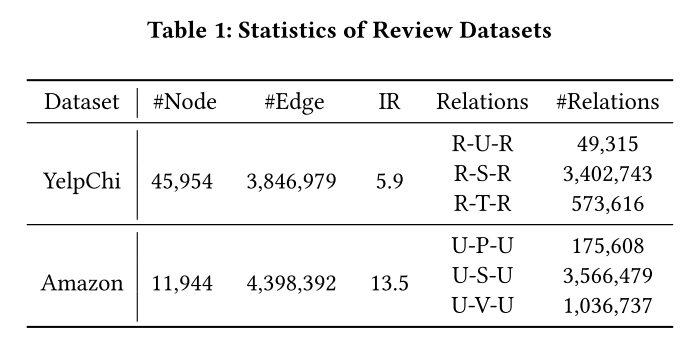
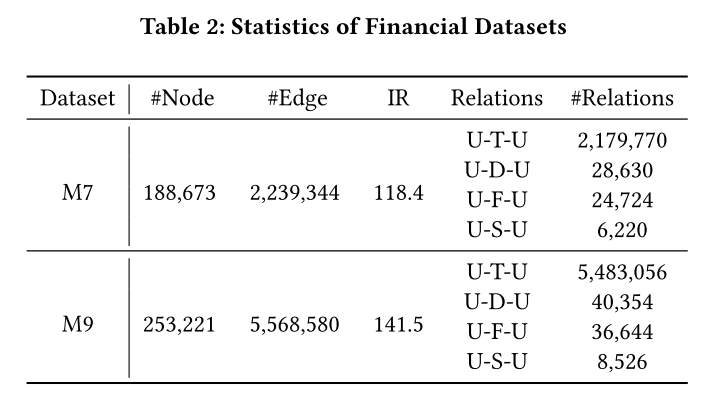
- 数据集:作者使用了两个公开的评论欺诈检测数据集(YelpChi 和 Amazon)以及两个来自阿里巴巴的实际金融欺诈检测数据集(M7 和 M9)。
- 比较方法:PC-GNN 与一系列最先进的图神经网络模型进行对比,包括 GCN、GAT、GraphSAGE 等。
- 评估指标:使用三个广泛应用的指标来评估模型性能,即 F1-macro、AUC、GMean。
- 消融实验:为了进一步验证模型中各个模块的有效性,设计了两种 PC-GNN 的变体进行消融实验。
- 参数敏感性分析:通过改变训练集的大小,分析模型对训练数据量的敏感性。
- 增强其他GNN模型:将PC-GNN的关键模块应用到传统GNN模型(如 GCN 和 GraphSAGE)中,测试其增强效果。
效果总结:
- 实验结果表明,PC-GNN显著优于现有的最先进方法,尤其是在处理高度不平衡的图数据时表现尤为出色。
- 在所有实验数据集上,PC-GNN 在 AUC 和 GMean 指标上都有显著的提升,展示了其在不平衡节点分类任务中的强大能力。
- 消融实验显示,Pick 和 Choose 两个模块都对模型性能有显著贡献,证明了其设计的合理性。
- 模型在不同的训练数据比例下表现出较强的鲁棒性,说明 PC-GNN 能够很好地适应不同规模的训练集。
4.1 实验设置
数据集:
YelpChi 和 Amazon 数据集用于评论欺诈检测任务。
- YelpChi 数据集包含酒店和餐馆的评论,图中的节点代表评论,边表示评论之间的关系,节点特征是100维的向量。
- Amazon 数据集是产品评论,图中的节点代表用户,边表示用户之间的关系。
M7 和 M9 是来自阿里巴巴的金融欺诈检测数据集,用于检测默认用户。
- 这两个数据集分别收集了2018年7月和9月的用户交易行为。
- 节点表示用户,边表示用户之间的交易、登录、资金转移或社交关系。
比较方法:
- GCN、GAT、GraphSAGE:经典的图神经网络模型,分别基于图卷积、图注意力和固定邻居采样机制。
- DR-GCN、GraphSAINT、GraphConsis、CARE-GNN:为处理类不平衡问题而设计的先进图神经网络模型。
- PC-GNN 变体:为了验证 PC-GNN 的两个核心模块(Pick 和 Choose)的效果,设计了两个变体:
- PC-GNN\P:去掉 Pick 模块。
- PC-GNN\C:去掉 Choose 模块。
评估指标:
- F1-macro:各类的 F1 分数的平均值。
- AUC:ROC 曲线下的面积,衡量模型对正负样本的区分能力。
- GMean:True Positive Rate 和 True Negative Rate 的几何平均数,特别适合不平衡分类任务。
实验环境:
- 所有实验在 Ubuntu 16.04 服务器上运行,使用了 PyTorch 1.6.0 和 DGL 框架。
4.2 性能比较(RQ1)
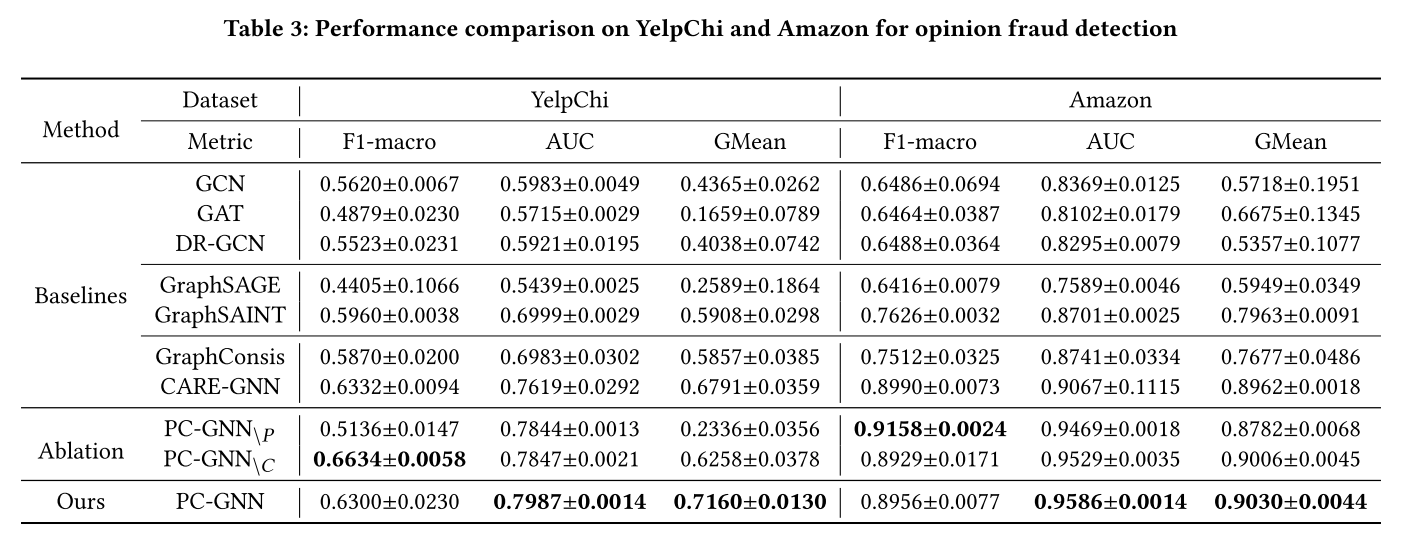
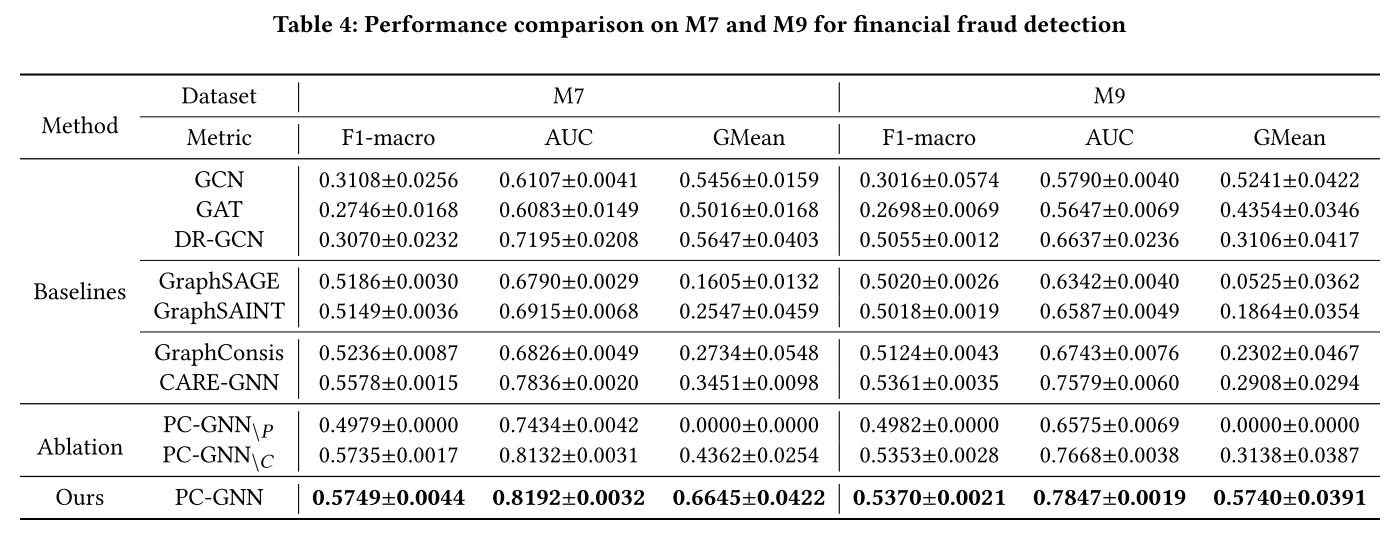
为了回答 RQ1,作者在评论欺诈检测任务和金融欺诈检测任务上对所有对比方法进行了评估,并记录了它们的 F1-macro、AUC 和 GMean 分数。
评论欺诈检测任务:
- PC-GNN 在 YelpChi 和 Amazon 数据集上,均取得了最好的 AUC 和 GMean 分数,表明它能有效处理不平衡图结构。
- 尤其是在 AUC 上,PC-GNN 的表现比 CARE-GNN 和 GraphConsis 提升了约 3%~5%,在 GMean 上提升了 0.7%~28%。
金融欺诈检测任务:
- 在高度不平衡的 M7 和 M9 数据集上,PC-GNN 在 F1-macro 和 AUC 上也取得了最好的结果。
- 与 GraphSAGE 和 GraphSAINT 相比,PC-GNN 的提升尤为明显,说明其设计的 Pick 和 Choose 模块在处理严重不平衡数据时尤为有效。
4.3 消融实验(RQ2)
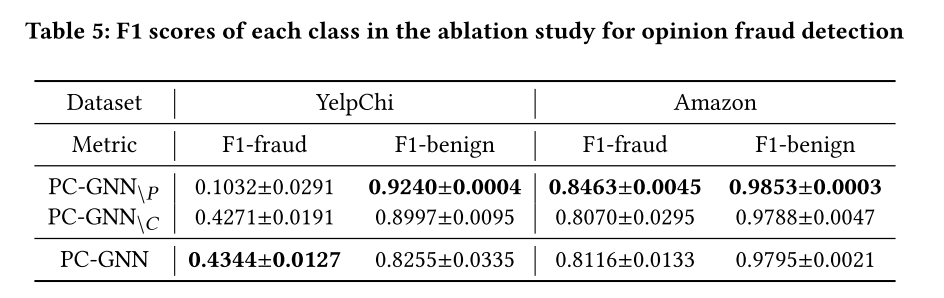
为了回答 RQ2,作者设计了消融实验来验证 Pick 和 Choose 两个模块的有效性,具体通过去除这两个模块分别得到 PC-GNN\P 和 PC-GNN\C。
在金融数据集上的表现:
- PC-GNN\P 在 M7 和 M9 数据集上没有产生正预测结果,说明去掉 Pick 模块对处理高度不平衡数据的负面影响极大。
- PC-GNN\C 相比 PC-GNN 在所有指标上均有所下降,验证了 Choose 模块对于少数类节点邻居选择的重要性。
在评论数据集上的表现:
在 YelpChi 和 Amazon 数据集上,去除 Pick 和 Choose 模块均导致性能下降,尤其是在少数类(即欺诈类)节点的 F1 分数上。
然而,在 Amazon 数据集中,由于图规模较小,PC-GNN\P 的表现略优,这表明在小规模图中全局训练可能比子图训练更有效。
4.4 参数敏感性分析(RQ3)
为了回答 RQ3,作者进行了训练比例的敏感性分析,通过改变训练数据的比例,分析模型性能的变化。
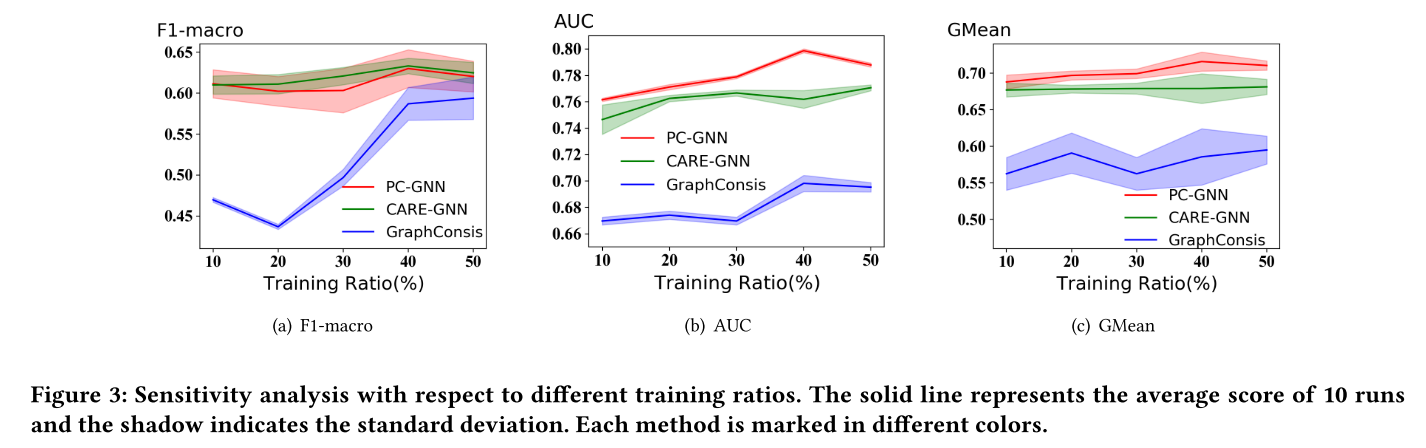
- 实验结果显示,在不同的训练比例下,PC-GNN 的 AUC 和 GMean 分数始终优于 GraphConsis 和 CARE-GNN。
- F1-macro 分数在较低的训练比例下有所波动,但随着训练数据的增加,PC-GNN 的表现逐渐趋于稳定。
4.5 增强其他 GNN 模型(RQ4)
为了回答 RQ4,作者将 PC-GNN 的 Pick 和 Choose 模块应用到传统的 GNN 模型中,具体为 GCN 和 GraphSAGE,并测试其增强效果。
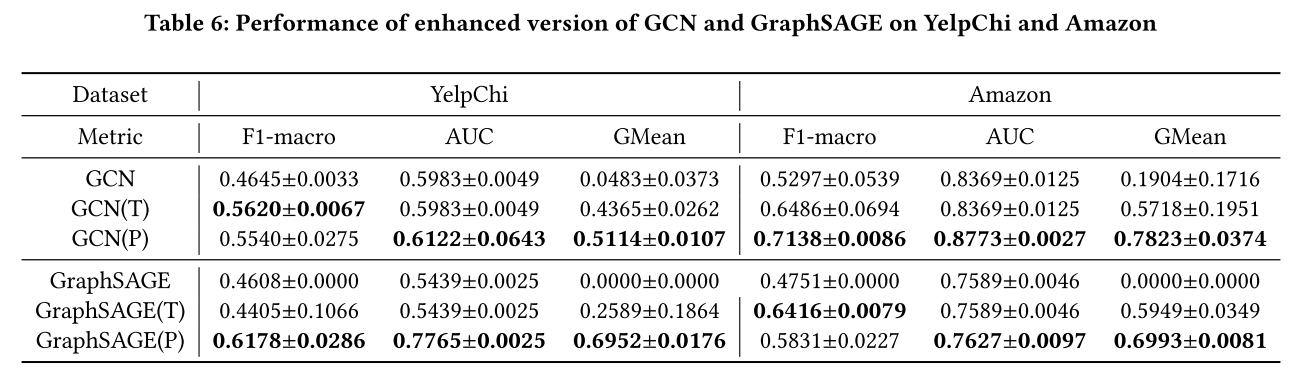
- 实验结果显示,加入 Pick 模块后,GCN(P) 和 GraphSAGE(P) 在所有指标上均有显著提升。
- 这表明,PC-GNN 的采样策略可以作为通用模块,增强其他传统 GNN 模型的性能。
5. 相关工作
在本部分,作者介绍了与本研究相关的两个主要领域的已有工作,即不平衡学习和基于图的欺诈检测。这些领域中的研究为 PC-GNN 的设计提供了启发和基础。
5.1 不平衡学习(Imbalanced Learning)
处理不平衡数据问题的现有算法可以分为两大类:重采样方法和重加权方法。
1. 重采样方法(Re-sampling Methods)
重采样方法包括过采样和欠采样两类。
- 过采样:增加少数类的样本数。常用的过采样方法包括随机过采样(ROS)和基于插值的过采样方法 SMOTE,以及一些生成方法(如GLGAN、ADAAR),这些方法通过生成合成样本来增强少数类。
- 欠采样:通过减少多数类的样本数来平衡类分布。典型的方法有随机欠采样(RUS)、EasyEnsemble 和 BalanceCascade 等,这些方法主要是为了解决过度采样时可能引入的噪声问题。最近,TRUST 提出了通过元学习强化学习来自动学习欠采样策略。
2. 重加权方法(Re-weighting Methods)
重加权方法主要通过为不同的样本或类别分配不同的权重来解决不平衡问题。
- 基于代价敏感的加权方法:如 Focal Loss 和 Dice Loss,这些方法通过降低容易分类的样本的权重,来减少这些样本在训练过程中的影响。
- 基于元学习的加权方法:如 Learning to Re-weight,这些方法通过动态调整每个样本的权重,优化训练过程中的梯度方向。
其他方法
除了重采样和重加权方法外,迁移学习、度量学习等方法也被用于解决类不平衡问题。然而,这些方法大多在传统特征空间中被研究,而图结构数据的类不平衡问题相对较少被探索。PC-GNN 针对图结构中的类不平衡问题,提出了新的图采样和邻居选择方法,填补了这一领域的研究空白。
5.2 基于图的欺诈检测(Graph-based Fraud Detection)
欺诈检测任务中的图数据通常包含用户的多种行为关系,构成异构图。因此,近年来许多工作基于异构图的分析来进行欺诈检测。作者将现有的基于图的欺诈检测工作分为两类:金融欺诈检测和评论欺诈检测。
1. 金融欺诈检测(Financial Fraud Detection)
金融欺诈检测的目标是基于金融平台的用户行为数据来检测恶意账户、违约用户和欺诈交易。
- GEM:适应性地学习异构账户-设备图的区分嵌入,以检测恶意账户。
- Semi-GNN:使用分层注意力机制的半监督 GNN 模型,用于解释性欺诈预测。
- GAL:提出了一种图异常损失函数,训练 GNN 生成可检测异常的节点表示。
- MAHINDER:在多视图异构信息网络中探索元路径,用于检测违约用户。
2. 评论欺诈检测(Opinion Fraud Detection)
评论欺诈检测的目标是检测误导消费者的垃圾评论或发布垃圾评论的欺诈用户。
- FdGars:基于图卷积网络(GCN)进行在线应用评论系统中的欺诈者检测。
- GAS:整合异构图和同构图来捕获评论的局部上下文和全局上下文。
- GraphConsis:研究了基于图的欺诈检测中的上下文不一致、特征不一致和关系不一致问题。
- CARE:通过增强 GNN 聚合过程,提出了一种防伪装的 GNN 模型,用于评论欺诈检测。
本研究的独特性
与上述方法不同,大多数现有工作通常采用简单的随机过采样方法来处理图中的类不平衡问题。而 PC-GNN 创新性地提出了Pick 和 Choose 两个模块,通过标签平衡采样器和邻居采样器来处理图结构中的不平衡问题。这种新方法能够更好地解决类不平衡带来的挑战,并且在多个数据集上表现优异。